Unterabschnitte
Bei der Mustererkennung wird in einem
Text ein
Muster gesucht. Anwendung ist zum Beispiel eine Textverarbeitung, bei der ein String im Text gesucht wird. Aber es gibt auch andere Anwendungsbereiche, z.B. DNA Analyse oder Virenerkennung.
Bei dem naiven Verfahren setzen wir das Muster immer um eine Position nach vorne und testen alle Stellen durch, ob kein Mismatch auftritt.
Dies erfordert dann
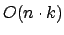
Zeit.
Beim KMP-Algorithmus geht es darum, daß Muster, welches an den Text gelegt wird, um schon besuchte Zeichen im Text nach vorne zu schieben, bei denen man sicher gehen kann, daß sie nicht mit dem Wort übereinstimmen. Dafür benötigen wir eine Hilfsfunktion, welche einmalig für das Suchwort erstellt wird. In dieser Hilffunktion ist aufgezeichnet, wie groß der Rand des aktuellen schon verglichenen Präfixes des Suchwortes ist, wenn genau an der Stelle ein Fehler auftritt. Beispielsweise ist der Rand von
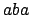
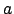
, da das
sowohl vorne als auch hinten vorhanden ist. Der Rand von
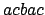
ist
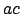
. Der Rand für
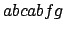
ist
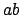
, falls nur bis zur 5. Position gelesen wird. In der Hilfsfunktion wird jeweils gespeichert, wie groß der Rand ist. Beispiel:
Der Text wird nun überprüft, indem das Muster darunter gelegt wird. Wenn ein Mismatch auftritt, verschieben wir das Muster um
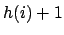
Stellen nach vorne. Also die Zahl in der Hilfsfunktionstabelle an der Stelle stehend +1.
Die Laufzeit dieses Verfahrens ist
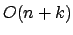
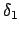
:
| Fall |
Aktion |
| 1. X kommt in dem Muster rechts neben dem Zeiger vor / Die aktuelle Position hat einen Mismatch, da das Zeichen im Text X ist im Muster aber nicht |
Eine Position nach rechts verschieben. Der Worst-Case tritt dann auf, wen wir beispielsweise einen Text aus nur a's haben und das Muster baa in diesem suchen. Jedesmal wird ein Mismatch a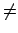 b erzeugt und es darf nur eine Position weiter gerutscht werden. b erzeugt und es darf nur eine Position weiter gerutscht werden. |
| 2. X kommt in dem Muster links neben dem Zeiger vor. / Im Text steht ein X aber im Muster nicht. |
Das Muster wird so verschoben, daß das erste X im Suchstring an der Zeigerposition steht. |
| 3. Es gibt gar kein X im Muster |
Wir können das Muster um die ganze Länge des Musters nach rechts verschieben. |
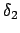
: Diese Heuristik ist dafür da, um den Fall 1 besser zu machen, d.h. um mehr Stellen nach rechts zu gehen.